- はじめに
- Delta Lake (デルタレイク) とは
- Delta Lake の実体
- Delta Lake が生まれた経緯: データレイクと Delta Lake の違い
- Delta Lake の特徴
- Delta Lake を実現する仕組み
- まとめ
- 参考
はじめに
2022年6月に開催されたDATA+AI SUMMITで、今までDatabricksでしか使えなかった機能を含む全てのDelta Lakeの機能がオープンソース (OSS) 化されるという発表があったのは記憶に新しい。そこで今回は「Delta Lakeとは何か」についてまとめる。
環境情報
Databricks Runtime Version: 10.4 LTS (includes Apache Spark 3.2.1, Scala 2.12)
ちなみに気づいたらDelta Lakeのマスコットがスポンジボブに出てきそうな可愛くないカニになっていたのですが、何があったのでしょうか…

Delta Lake (デルタレイク) とは
オープンソースのデータフォーマットであるDeltaは、Parquetファイルとトランザクションログ(Delta Log)から成り立っている。Delta形式のフォーマットを用いて構築されたテーブルは、Deltaテーブルと呼ばれ、Deltaテーブルのデータストアを、Delta Lake (デルタレイク) と呼ぶ。多くの場合、データの実体はAWS S3などのオブジェクトストレージ上 (データレイク) に保管されている。
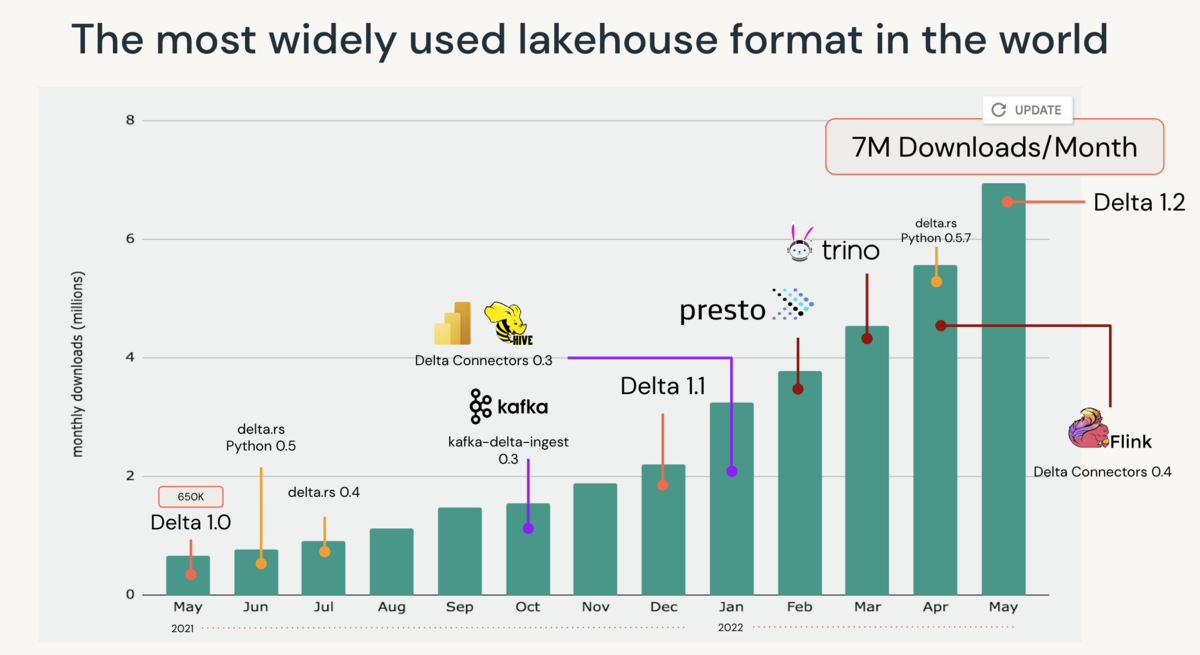
また2022年05月時点で月間ダウンロード数は700万を超えており、ストレージフォーマットとして広く認知されている。
*データレイクについてはこちらの記事をご参照ください。
→ データレイクについて理解する
Delta Lake の実体
Delta Lakeの実体は、Parquetで保存されたデータファイルと全てのトランザクションを記録したトランザクションログ (Delta Log) から成り立っている。
Delta Lake の構造
ParquetファイルからDeltaテーブルを作成して、Deltaの構造を確認する。
(1) ParquetファイルからDeltaテーブルを作成する
source_path = 'dbfs:/databricks-datasets/samples/lending_club/parquet/' df_parquet = spark.read.parquet(source_path) # マネージドテーブルとして保存: pathの指定なし df_parquet.write.format("delta").mode("append").saveAsTable("demo_delta_table")
*マネージドテーブルについてはこちらの記事をご参照ください。
→ Delta テーブルを作成する
(2) 作成したDeltaテーブルの格納先を表示する
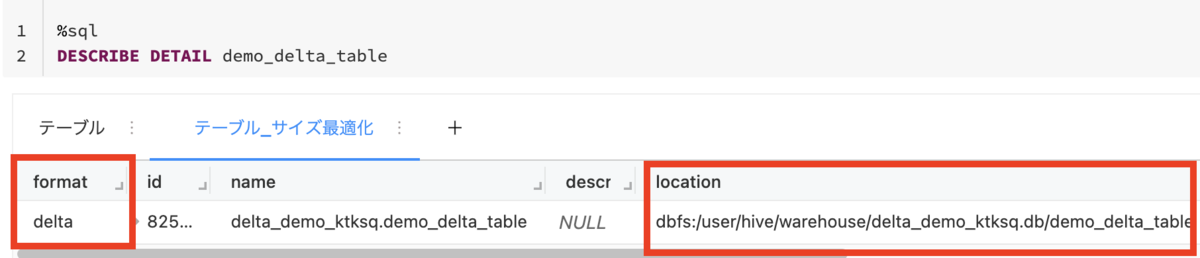
%sql DESCRIBE DETAIL demo_delta_table
→ dbfs:/user/hive/warehouse/...にDeltaテーブルの実体が格納されていることがわかる
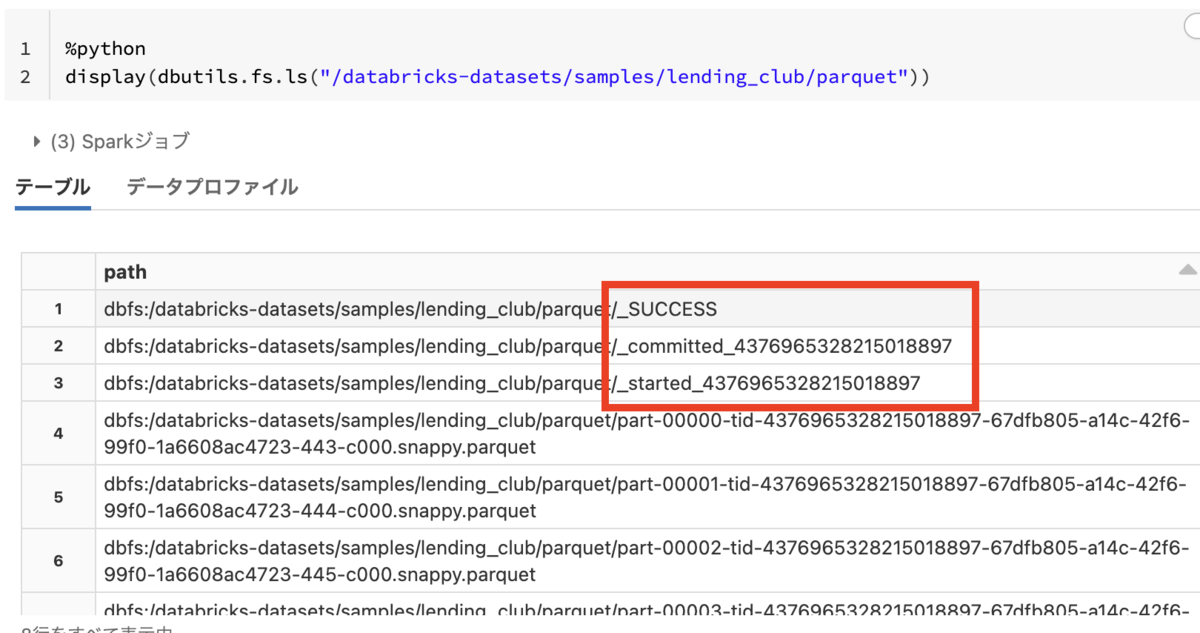
(3) Deltaテーブルに格納されているファイルを確認する
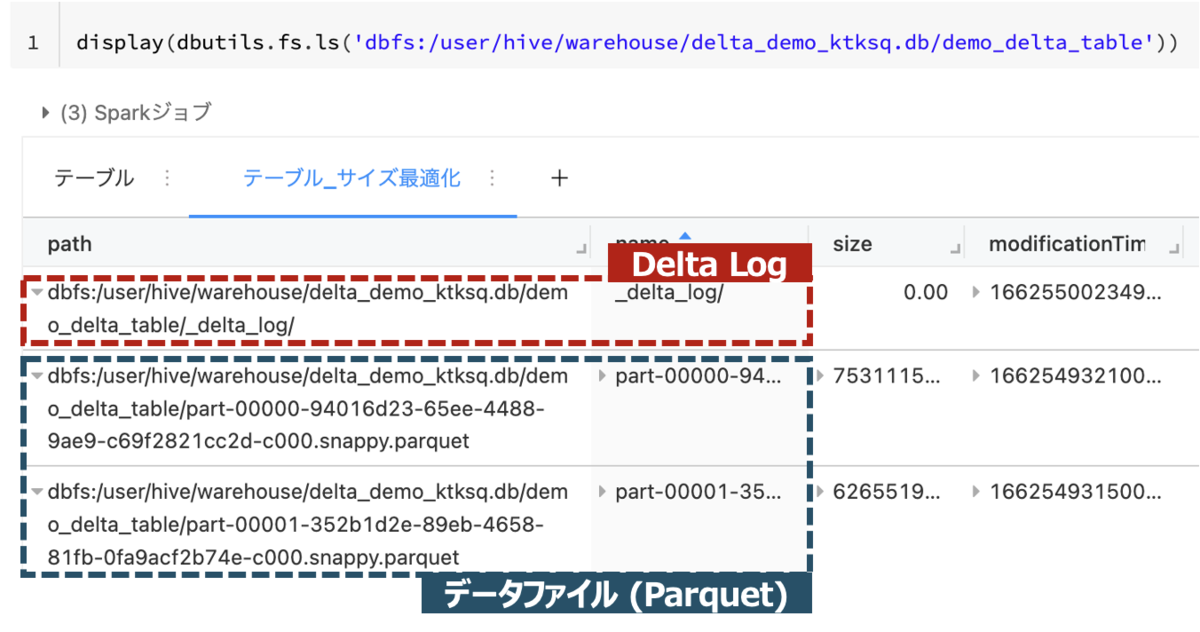
display(dbutils.fs.ls('dbfs:/user/hive/warehouse/delta_demo_ktksq.db/demo_delta_table'))
→ Deltaの実体がParquetで保存されたデータファイルと_delta_logディレクトリであることがわかる
*_delta_logディレクトリの内部構造についてはこちらの記事をご参照ください。
→ Delta Logについて理解する
Parquet と Delta の相違点
ここからは、ParquetとDeltaのファイル構造の違いについて説明する。
Parquetとは何か
Parquetとは主にHadoopのエコシステムで使われるカラムナ(列指向)フォーマットのこと。カラムナフォーマットは圧縮性とパフォーマンスに優れているため、分析的なクエリに適している。
・高いデータの利用効率
CSVのような行指向のフォーマットと比べて、不必要なカラムを読まずに済む。加えて、内部で行方向に一定の単位でメタ情報を保持することによりスキャン範囲を限定できる水平パーティショニングの機能も持っているため、効率的にクエリを実行することができる。
・高い圧縮効率
カラムナフォーマットは、同じ属性のデータが集まる列方向にデータを圧縮することでデータの圧縮効率を高めることができる。
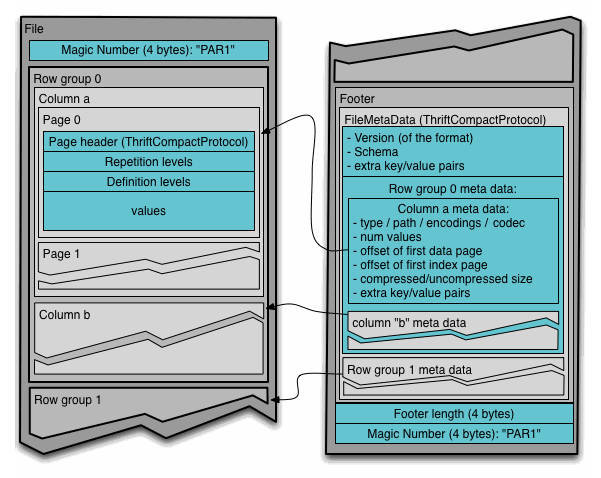
Parquetの構造
Parquetの構造を確認すると、_delta_logディレクトリが存在していないことがわかる。その代わりに_started_< id >と_committed_< id >で始まるメタデータファイルがParquetファイルと一緒に保存されている。これらのファイルは、DBIOトランザクションプロトコルによって作成されており、一般的に直接変更することは推奨されていない。
*DBIOトランザクションプロトコル: Databricksが実装した独自のトランザクションコミットのこと。Databricks環境以外でSparkアプリケーションを動作させる場合は、Sparkのデフォルトのコミットプロトコルが用いられる。
Parquet と Delta の違い
Parquet と Delta の大きな違いは、Delta トランザクションログのセントラルレポジトリである_delta_logディレクトリの有無である。トランザクションログ (Delta Log) が存在することで、Delta でのACIDトランザクション、スケーラブルなメタデータ処理、タイムトラベルなどを可能にしている。
Delta Lake が生まれた経緯: データレイクと Delta Lake の違い
データ分析の重要性の高まりとともに、安価なストレージでさまざまな形式の生データを扱うことができるデータレイクが登場した。データベースからデータレイクへの移行はコンピュートとストレージを独立して拡張できるという大きな利点があった。しかしデータベースからデータレイクへ移行することで、データの信頼性や品質が失われ、メタデータ管理の欠如によるデータスワンプ問題が発生した。
*Data Swamp (データスワンプ): メタデータを管理することなく、データをただ貯めることでデータ情報がブラックボックス化してしまっている状態のこと
データレイクのメリット
(1) コンピュートとストレージの分離
(2) 無限のストレージ容量
(3) 安価なストレージコスト
(4) あらゆる種類の生データを保存 (e.g. 非構造データ、構造化データ、ビデオ、オーディオ、テキスト)
データレイクの課題 *Parquetで構築した場合
(1) ACIDトランザクションが担保されていないため、部分的に完了したトランザクションによりデータが破損した状態で残り、複雑なリカバリが必要になる
(2) データ品質が担保できないため、一貫性がなく使い物にならないデータが作成される
(3) 一貫性/独立性がないため、データの追加とデータの読込み、バッチとストリーミングを同時に実行させることが困難
(4) 多くの小さいサイズのファイルが存在するため、ファイルI/Oに時間がかかる
(5) クラウドストレージのスループットが低い (S3は20~50MB/scoreに対して、ローカルのNVMe SSDは300MB/score)
そのためデータレイクにデータの信頼性と品質、そしてパフォーマンスを付加するために、Delta Lakeが開発された。
Apache Sparkのオリジナルクリエイターによって開発されたDelta Lakeは、オンライン分析処理 (OLAPスタイル) のために、データベースのトランザクションの信頼性とデータレイクの水平スケーラビリティという両者の長所を組み合わせるように設計されている。
Delta Lake の特徴
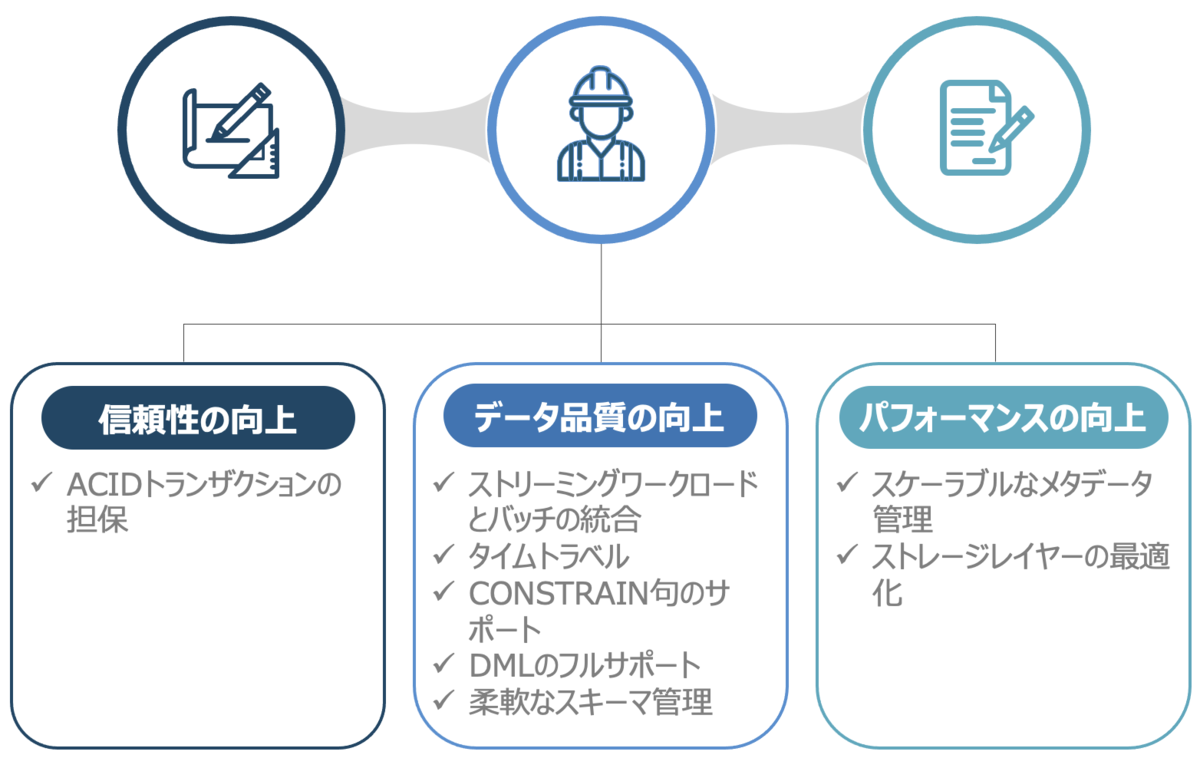
Data Lake (データレイク) と比べて、Delta Lake (デルタレイク) には大きく3つのメリットがある。
・信頼性の向上
・データ品質の向上
・パフォーマンスの向上
本セクションではこのメリットを支えるDelta Lakeの機能について説明する。
ACIDトランザクションの担保
Delta Lakeはデータレイク上の全ての操作をトランザクション化することで、データの信頼性と整合性を最大限に高めている。トランザクションとは、以下で説明する4つの特性 (ACID特性) を備えた不可分な一連の処理単位のことを言う。またACID特性を備えたデータベース操作のことをACIDトランザクションと呼んでいる。
Delta Lakeはデータレイク上でのACIDトランザクションを可能にすることで、部分的にしか操作を完了できなかった場合でも、データの一貫性を保てるように設計されている。ACIDトランザクションでない場合は、処理の途中で障害が発生すると、データは一部分しか保存されない可能性がある。
*信頼性: 意図する処理と結果が一貫している特性のこと
Atomicity (原子性):
トランザクションは完全に終了 (COMMIT) するか、もしくは実行前の状態に戻す (ROLLBACK) かのどちらかの状態をとる必要がある。
トランザクション内の各ステートメント (データの読取り、書込み、更新、削除) は1つの実行単位として扱われ、ステートメント全体が実行されるか、あるいは何も実行されないかのどちらかの状態にしかならない。この特性により、たとえばストリーミングデータソースが途中で故障した場合でも、データの損失や破損が発生するのを防ぐことができる。
Consistency (一貫性):
トランザクション処理では実行前後でデータの整合性を持ち、一貫したデータを確保する必要がある。
トランザクションの一貫性により、データの破損やエラーがテーブルの整合性に意図しない結果をもたらすことがないようにしなければならない。
Isolation (独立性):
複数のトランザクションがそれぞれ独立して実行できる必要がある。
つまり複数のユーザが同じテーブルから一度に読み書きする場合、各トランザクションを分離することで、同時進行するトランザクションが互いに干渉したり影響を与えないようにしなければならない。
Durability (耐久性):
正常に実行されたトランザクションによって行われたデータの変更は、システム障害が発生した場合でも確実に保存される必要がある。
スケーラブルなメタデータ管理
Delta Lakeは、Delta Logと呼ばれるメタデータとデータファイルを一緒にデータレイク上に格納することでスケーラブルなメタデータ管理を可能にしている。
Delta Lakeは、他の多くのストレージフォーマットやクエリエンジンとは異なり、すべてのメタデータ処理をSparkを利用してスケールアウトするため、メタデータを効率的に処理することができる。
メタストアにすべてのメタデータが格納されていると、データが頻繁に変化する場合にはメタストアに保存する情報量そのものがビッグデータとなり、スケーラブルなメタデータ処理に課題があった。そのためDelta Lakeでは、メタストアに基本的なメタデータの詳細を残しつつ、重要な詳細のほとんどをDelta LogにParquet形式で保存している。
*Delta Logについてはこちらの記事をご参照ください。
→ Delta Logについて理解する
バッチとストリーミングワークロードの統合
Delta Lakeのテーブルは、バッチ処理とストリーミングのソースおよびシンクの両方で動作する機能を備えており、readStreamとwriteStreamを通して、Spark Structured Streamingと密接に統合されている。
Delta Lakeは、以下のようなストリーミング時の課題を解決する:
・低レイテンシーのインジェストで生成された小さなファイルの統合
・複数ストリーム (または同時実行のバッチジョブ) による "Exactly Once"処理の実現
・ファイルをストリームのソースとして使用する際に、新規作成ファイルを効率的に検出
タイムトラベル (バージョン管理)
タイムトラベルとは、Delta Lakeがデータレイクに保存されているデータのバージョン管理を自動的に行うことで、簡単に以前のバージョンのデータにアクセスし、元に戻すことができる機能である。
Deltaトランザクションログ (Delta Log) が、データに加えられたすべての変更に関する詳細を記録し、変更の完全な監査証跡を保持していることで、タイムトラベルを可能にしている。タイムトラベルは、ETLパイプラインやデータ品質の問題のトラブルシュート、または偶発的に発生したデータパイプラインの修正や機械学習時のモデルや実験の再現性を担保するのに用いられている。
*タイムトラベルで過去データを参照する方法についてはこちらの記事をご参照ください。
→ タイムトラベルで過去データを参照する
CONSTRAINT句のサポート
データの品質と整合性を自動的に検証するために、Delta Lakeは標準SQLのCONSTRAINT句をサポートしている。もし制約に違反した場合は、InvariantViolationExceptionをスローし、新しいデータを追加することはできない。
サポートしているCONSTRAINT句は以下の2種類である。
・NOT NULL制約: 特定の列の値にNULL値が入力されるのを禁止する
・CHECK制約: 条件を指定し、条件を満たさないデータの追加を禁止する
DML (データ操作言語) のフルサポート
多くの分散処理フレームワークでは、データレイクのアトミックなデータ変更操作をサポートしていない。
一方で、Delta LakeはMERGE、UPDATE、DELETE操作をサポートし、チェンジデータキャプチャ (CDC)、スローチェンジディメンション (SCD)、ストリーミングアップサートを含む複雑なユースケースを可能にしている。
*DML操作についてはこちらの記事をご参照ください。
→ Delta LakeでDML操作を行う
UPDATE
UPDATEオペレーションを使用することで、フィルタリング条件 (述語) にマッチする行を選択的に更新することができる。具体的には、述語に一致する各ファイルをメモリに読込み、関連する行を更新し、その結果を新しいデータファイルに書き出す。またDelta Lakeはデータスキッピングを用いてこのプロセスを高速化している。
DELETE
DELETEオペレーションを使用することで、フィルタリング条件 (述語) にマッチする行を選択的に削除することができる。
DELETEはUPDATEと同じように動作し、以下の2ステップでデータを削除している。
(1) 最初のスキャンで、述語の条件に一致する行を含むデータファイルを識別して抽出する
(2) 2回目のスキャンで、一致するデータファイルをメモリに読込み、関連する行を削除し、新しいデータファイルに書込む
MERGE
MERGEオペレーションを使用することで、UPDATEとINSERTを組合せた「UPSERT (アップサート) 」を実行することができる。
UPSERTの動作を理解するために、既存テーブル (ターゲットテーブル) と 新しいレコードと既存のレコードの更新が混在しているソーステーブルの例で考える。
(1) ソーステーブルのレコードが、ターゲットテーブルの既存レコードと一致する場合、該当のレコードを更新する
(2) 一致するレコードがない場合、新しいレコードを挿入する
Delta Lakeは2ステップでデータをMERGEしている。
(1) ターゲットテーブルとソーステーブルの間で内部結合 (Inner join) を行い、マッチするファイルをすべて選択する
(2) ターゲットテーブルとソーステーブルの選択されたファイル間で外部結合 (Outer join) を実行し、更新/削除/挿入されたデータを新しいデータファイルに書込む
柔軟なスキーマ管理
Delta Lakeでは、状況に応じで柔軟にスキーマ管理を行うことができる。
スキーマ エンフォースメントを用いることで、ユーザがミスやゴミデータで意図せずテーブルを汚してしまうことを防ぐことができる。一方で意図したスキーマの変更を行いたい場合は、スキーマ エボリューションを用いることで、自動的に追加することができる。
1. スキーマ エンフォースメント
スキーマエンフォースメント (スキーマ強制) とは、スキーマバリデーションとも呼ばれ、既存テーブルのスキーマと一致しないデータの挿入を自動的に防止することで、データの品質を確保することができる。
Delta Lakeは、書込み時にスキーマ検証を行う。つまり、あるテーブルへの新しい書込みはすべて、書込み時にターゲットテーブルのスキーマと互換性があるかどうかチェックされる。スキーマに互換性がない場合は、Delta Lakeはトランザクションを完全にキャンセルし、ユーザに不一致を知らせるために例外を発生させる (データは書き込まれない) 。
スキーマエンフォースメントは、メダリオンアーキテクチャのゴールドテーブルのように強い型付けが必要な場合に使用され、データ品質を担保している。
Delta Lakeは以下のルールに従い、テーブルへの書込みが互換性があるかどうかを判断する。
・ターゲットテーブルのスキーマに存在しない追加のカラムを含むことはできない。
・ターゲットテーブルのカラムのデータ型と異なるデータ型を含むことはできない。
・大文字と小文字が異なるだけの列名を含むことはできない。(e.g. 同じテーブルに 'Foo' と 'foo' のようなカラムを定義することはできない)
2. スキーマ エボリューション
スキーマエボリューション (スキーマ拡張) とは、時間と共に変化するデータに対応するために、ユーザが簡単にテーブルの現在のスキーマを変更できるようにする機能である。一般的に、追加や上書きを行う際に使用され、1つまたは複数の新しいカラムを含めるためにスキーマを自動的に適応させる。
上述したように、デフォルトではDelta Lakeは不正なスキーマを自動的に防止する。
一方で必要に応じて、テーブルスキーマを拡張させる場合には以下の2通りの方法がある。
(1) .write または .writeStreamコマンドに .option('mergeSchema', 'true') を追加する
(2) Sparkの設定に spark.databricks.delta.schema.autoMerge = True を追加する (Sparkセッション全体に対して有効化)
*スキーマ エボリューションの方法についてはこちらの記事をご参照ください。
→ スキーマを更新する
ストレージレイヤーの最適化
Delta Lakeは、ストレージ内のデータのレイアウトを最適化することで、クエリパフォーマンスを向上させている。例えば、下図のようにデータの大きさに偏りがあったり、サイズの小さいファイルが多く存在する場合は、クエリパフォーマンスが低下する。そのためDelta Lakeには、ストレージレイヤーを最適化するためのさまざまな機能が存在している。
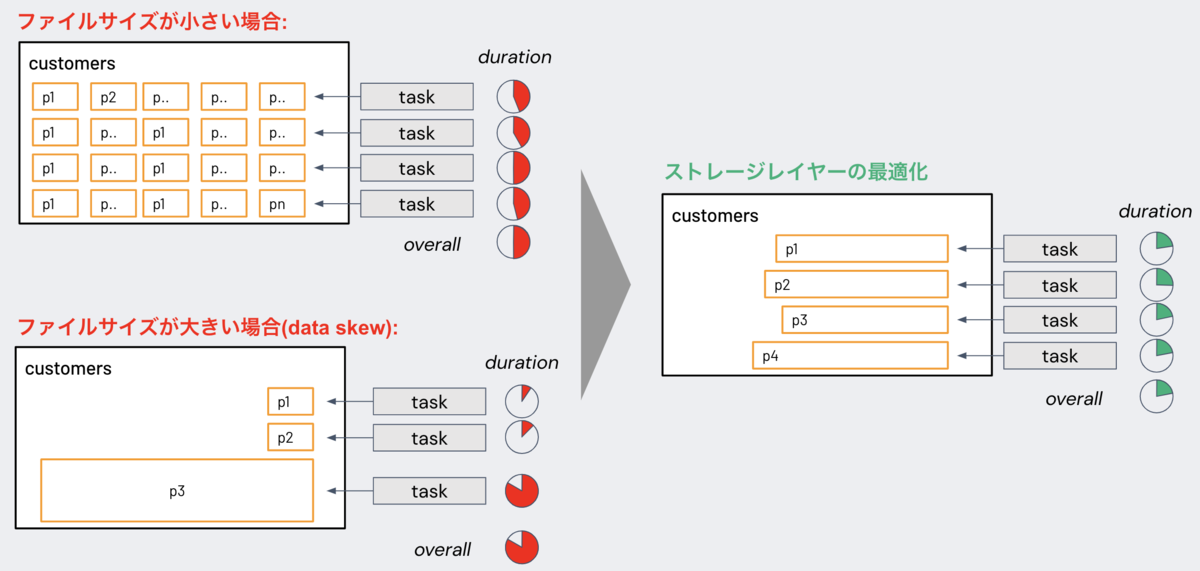
1. Data Compaction (Bin-packing)
Bin-packing (ビンパッキング) と呼ばれるデータのコンパクト化をすることで、多くの小さなファイルをより少ない大きなファイルにまとめ、ファイル数を削減している。
通常この処理にはコストがかかるため、ピーク時以外に実行するか、メインパイプラインとは別のクラスタで実行して、メインジョブの不要な遅延を回避するのを推奨している。また本処理はべき等であるため、新しいデータが到着していなければ、より頻繁に実行しても追加計算が発生することはない。
OPTIMIZEコマンドを実行することで、データをコンパクト化することができる。
from delta.tables import * deltaTable = DeltaTable.forName(spark, "events") # deltaTable = DeltaTable.forPath(spark, "/data/events") # pathを指定 deltaTable.optimize().executeCompaction() # deltaTable.optimize().where("date='2021-11-18'").executeCompaction() # where句で条件を指定
OPTIMIZE処理は、テーブル、ファイルパス、またはwhere節を指定することでテーブルのより小さなサブセットに対して実行することができる。
デフォルトのターゲット・ファイルサイズは1GBとなっている。optimize.minFileSizeとoptimize.maxFileSizeの2つのパラメータにバイト単位で値を指定することにより、デフォルトのファイルサイズを変更することができる。
またOPTIMIZEコマンドを実行するために並列実行されるスレッドの最大数のデフォルト値は、optimize.maxThreadsを調整することによって増やすことができる。
2. Auto-Optimize
Auto-Optimizeは、Deltaテーブルへの書込み時に自動的にファイルサイズの最適化を行うオプションである。
Auto-Optimizeは、以下のシナリオで特に推奨されている。
・数分オーダーのレイテンシーを許容するストリーミングの場合
・MERGE INTOをDelta Lake への書込み方法として使用する場合
・CREATE TABLE AS SELECTまたはINSERT INTOを用いる場合
Auto-Optimizeは、最適化された書込みと自動コンパクションという2つの機能から構成されている。
(1) 最適化された書込み
実際のデータに基づいてApache Sparkのパーティションサイズを動的に最適化し、各テーブルパーティションに対して128MBのファイルを書き出す。
*データセットの特性によって多少のサイズ変動が存在する。
(2) 自動コンパクション
データの書込みの後、ファイルをさらにコンパクト化できるかどうかをチェックし、小さなファイルが最も多いパーティションに対して、ファイルをさらにコンパクト化するためにOPTIMIZEジョブを実行する。
*標準のOPTIMIZEで使用する1GBファイルサイズではなく128MBファイルサイズで実行されることに注意する。
・新規テーブルに適用する場合
set spark.databricks.delta.properties.defaults.autoOptimize.optimizeWrite = true; set spark.databricks.delta.properties.defaults.autoOptimize.autoCompact = true;
・既存テーブルに適用する場合
ALTER TABLE [table_name | delta.`<table-path>`] SET TBLPROPERTIES (delta.autoOptimize.optimizeWrite = true, delta.autoOptimize.autoCompact = true)
・Spark Configに設定する場合
spark.databricks.delta.optimizeWrite.enabled spark.databricks.delta.autoCompact.enabled
3. Data skipping (データスキッピング)
各カラムの最小値と最大値のようなファイルレベルの統計値をデータを書き込む際に自動的に取集することで、不要なファイルI/Oを回避し高速なクエリを提供することができる。Delta Lakeは、ファイルレベルの統計情報をDelta Logに一元化し、クエリ時にフィルタ値が各ファイルの最小値以下または最大値以上の物理ファイルを完全にスキップできるようになった。そのため実際に開いて読込む必要のあるファイルの総数を大幅に削減することができる。
データスキッピング自体はユーザ側で設定する必要はなく、デフォルトで有効になっている。ただし効果はデータのレイアウトに依存するため、Z-Orderを一緒に適用することを推奨している。
文字列やバイナリのような長い値を含む列の統計情報を収集することは、高価な処理となるため避ける必要がある。テーブル プロパティとしてdelta.dataSkippingNumIndexedColsを設定すると、不必要な列の統計情報が収集されるのを防ぐことができる。このプロパティは、テーブルのスキーマにおける列の位置インデックスを示しているため、delta.dataSkippingNumIndexedColsより小さい位置インデックスを持つ列は統計が収集される。つまり長い値を含む列の統計情報の収集を避けるには2種類の方法が使用できる。
*ネストされた列内の各フィールドは、個別の列として見なされる。
- テーブルのスキーマで長い値の列がこのインデックスの後になるように
delta.dataSkippingNumIndexedColsプロパティを設定する - ALTER TABLE ALTER COLUMN を使用して長い値を含む列を
delta.dataSkippingNumIndexedColsプロパティを超えるインデックス位置に移動させる

*データスキッピングに使用される統計情報についてはこちらの記事をご参照ください。
→ メタデータについて理解する
4. Z-Order
Z-Order (多次元クラスタリング) は、同じファイルセットの中に関連する情報をまとめて配置するファイルレイアウト技術で、データスキッピングと共に使用することで読込みデータ量が大幅に削減される。 Z-Orderに使用するカラムには、WHERE句に頻繁に登場する、またはクエリのJOIN条件で使用される高カーディナリティ (多数の異なる値を持つ) のフィールドを指定する。一般的には、ユーザID、IPアドレス、プロダクトID、電子メールアドレス、電話番号などの識別子フィールドを指定する場合が多い。ファイルレイアウトでは、データがクラスタ化され、最小値と最大値の範囲が狭く、(理想的には)重複していない場合、データスキッピングの効果を最大化することができる。
ZORDER BYにカラムを指定すると、Z-Orderによるファイルレイアウトの最適化が実施される。Z-Orderにはカンマ区切りのリストとして複数のカラムを指定することができるが、カラムが増えるごとに局所性の効果は低下する (カラム数は3~4個が適当)。データスキッピングには列の統計情報が必要なため、統計が収集されていない列に対するZ-Orderは効果がない。
OPTIMIZE events WHERE date >= current_timestamp() - INTERVAL 1 day ZORDER BY (eventType)
Z-Orderにかかる時間は、複数回実行しても減少することは保証されない。一方で前回の実行以降に新規データが追加されていなければ、ノーオペレーションとなる。 Z-Orderは、タプル数に関して均等にバランスの取れたデータファイルを作成することを目的としているが、ディスク上のデータサイズに関しては必ずしも均等にはならない。
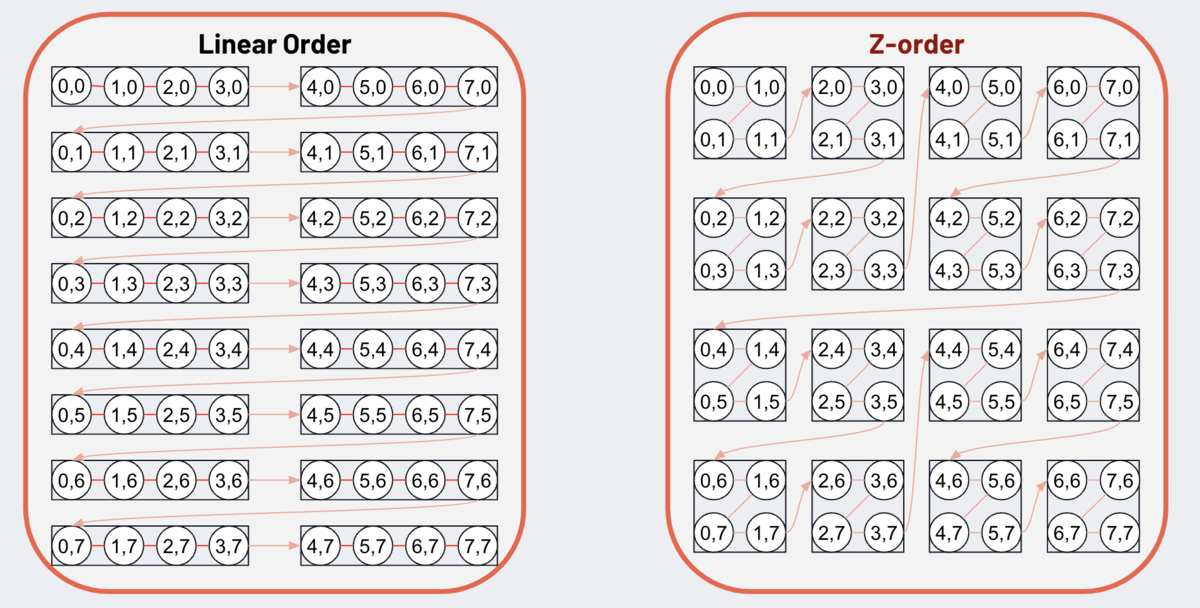
Z-Orderによるクエリの高速化を理解するために、各パーツファイルを読込んで、X = 2 またはY = 3を検索する場合を考える。その結果、Z-Orderによるファイルレイアウトの方が効率的にデータの読込みを行なっていることがわかる。

5. Delta Cache (デルタキャッシュ)
クラウドストレージのデータコピーをワーカーノードのSSDディスク上のローカルに作成することで、データの読込みを高速化する。 データはリモートロケーションからファイルを取得する必要があるたびに、自動的にキャッシュされる。Parquet / Delta形式がサポートされている。同じデータを連続して読込む場合はローカルで実行されるため、読込み速度が大幅に向上する。
ディスクキャッシュには、リモートデータのローカルコピーが含まれ、さまざまなクエリのパフォーマンスを向上させることができる。一方で任意のサブクエリの結果を保存することはできない。そのため任意のサブクエリデータの結果や、Parquet以外の形式 (CSV、JSON、ORCなど) で保存されたデータを保存する場合は、Sparkキャッシュを用いる。またSparkキャッシュとは異なり、ディスクキャッシュはシステムメモリを使用しない。
ディスクキャッシュを使用する場合は、クラスタを構成するときにSSDボリュームを持つワーカータイプを選択する必要がある。
ディスクキャッシュ (Delta Cache) を有効化/無効化するには、以下を実行する。
spark.conf.set("spark.databricks.io.cache.enabled", "[true | false]")
ディスク使用量は、以下のプロパティを設定することで変更できる。
・spark.databricks.io.cache.maxDiskUsage: キャッシュデータ用に確保されたノードごとのディスク容量 (bytes)
・spark.databricks.io.cache.maxMetaDataCache: キャッシュされたメタデータのために確保されたノードごとのディスク容量 (bytes)
・spark.databricks.io.cache.compression.enabled: キャッシュされたデータを圧縮形式で保存するかどうか
設定例
spark.databricks.io.cache.maxDiskUsage 50g spark.databricks.io.cache.maxMetaDataCache 1g spark.databricks.io.cache.compression.enabled false
Delta Lake を実現する仕組み
アトミック操作を実現する仕組み
Delta Lakeがアトミック操作を実現するための仕組みをこちらにまとめました。
記事が3万字を超えたので、別記事に切り分けましたが、
Delta Lakeを理解する上で重要なパートなので、ぜひ読んでみてください。
ACIDトランザクションを実現する仕組み
Delta Lakeは楽観的同時実行制御 (Optimistic Concurrency Control) と多版同時実行制御 (MVCC: MultiVersion Concurrency Control) を組合わせてACIDトランザクションを実現している。
楽観的同時実行制御
楽観的同時実行制御とは、データに対してのロックは行わずに,更新対象のデータが他のトランザクションとコンフリクトがなかったことを確認してからコミットを行う方法である。具体的には、トランザクションがコミットされる時点で、対象のコミット操作の結果が変更されるようなデータへの変更が行われていないことを確認することで、データの整合性を保証している。
多版同時実行制御
多版同時実行制御(MVCC: MultiVersion Concurrency Control)によって、同時実行される2つのトランザクションのうち,先発のトランザクションがデータを更新し,コミットする前に,後発のトランザクションが同じデータを参照すると,更新前の値を返すことを可能にしている。そのため、複数のユーザから同時にデータベースの更新要求を受け取った場合でも、同時並行性と一貫性の両方を保証できる。多版同時実行制御では、更新中のデータに対する参照要求に対してトランザクション開始時点のデータのコピー (スナップショット) を提供する。また参照中のデータに対する更新要求に対しても、トランザクション開始前のデータのコピーを提供する。これにより、読込みのロックと書込みのロックがコンフリクトすることがなくなり、トランザクションの同時並行性が向上する。
コンフリクトが発生した場合の対応
2つ以上のコミットが同時に行われた場合は、以下の相互排他のルールに従って解決する。このプロトコルにより、Delta LakeはACIDの原則である分離を実現し、複数の同時書込み後のテーブルの状態が、各書込みが互いに分離して連続的に行われた場合と同じ結果となることを保証する。つまりトランザクション分離レベルがSERIALIZABLE (直列化可能) であることを保証している。
*デフォルトの分離レベルはWriteSerializable
(1) テーブルの読込み:
テーブルの最新バージョンを参照し、変更すべきファイルを特定
(2) 書込み:
新しいデータファイルを書込むことによって、すべての変更を段階的に実施
(3) 検証→コミット:
変更に対して同時にコミットされた他の変更とのコンフリクトの有無を確認
・コンフリクトがない場合→すべての段階的な変更がコミットされ、書込み操作は成功
・コンフリクトがある場合→同時変更例外が発生して書込み操作が失敗
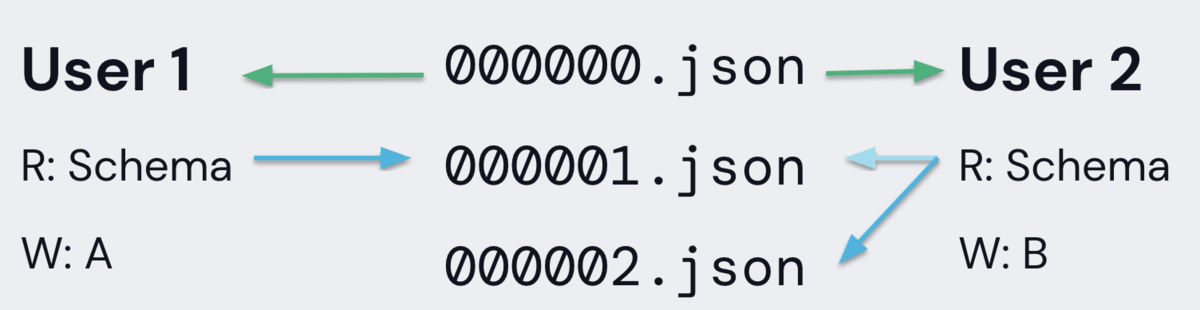
コンフリクト時の挙動を理解するために、2人のユーザによって同時にコミットが行われた場合を考える。
Delta Lakeは、変更を加える前に読み込んだテーブルの開始バージョン (バージョン0) を記録する。
ユーザ1と2が同時にテーブルにデータを追加する場合、どちらか1人のユーザだけが000001.jsonのコミットを成功させることができる。ここではユーザ1のコミットが通り、ユーザ2のコミットは拒否されている。
ユーザー2のコミットが拒否された後 (エラーは発生しない) 、コミットしようとしている操作の結果を変更するようなデータへの変更が行われたかどうかを確認する。コンフリクトしない場合は、新しく更新されたテーブルに対してユーザ2のコミットを再試行し000002.jsonとして正常にコミットする。
まとめ
今回はDelta Lakeについてまとめた。
また今回記事を作成するにあたり、参考にしたテキストは無料でダウンロードできますので、ぜひダウンロードしてみてください。