はじめに
MLflow Tracking, Projectsを使うことでモデルの学習を記録し、学習した環境と一緒にバンドルすることができるようになった。 そこで今回は、モデルをパッケージ化し、様々なデプロイメントツールで利用できるようにするための機能であるMLflow Modelsについてまとめる。プラットフォームに依存しない方法でモデルをパッケージングすることで、デプロイメントオプションの柔軟性が高まり、多くのプラットフォームでモデルを再利用することが可能になる。
環境情報
Databricks RunTime: 10.2 ML (includes Apache Spark 3.2.0, Scala 2.12)
前回までのMLflowシリーズ
- MLflow Tracking
- MLflow Projects
MLflowとは
前回の記事でまとめたので、そちらをご参照ください。 ktksq.hatenablog.com
MLflow Modelsとは
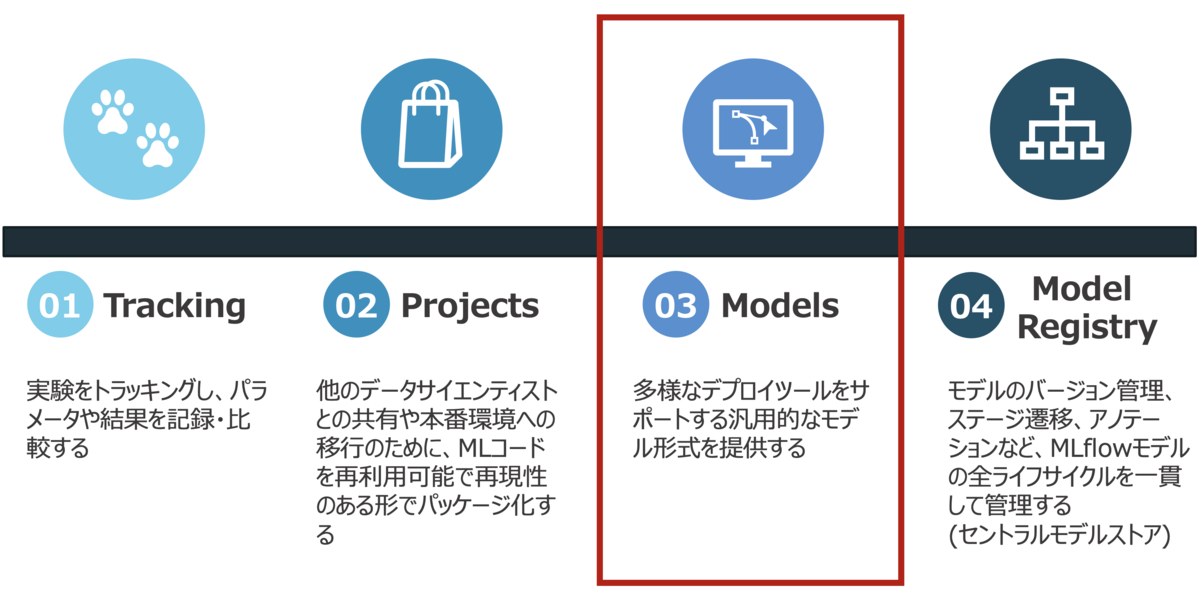
「フレーバー」という概念を用いてMLモデルをパッケージングするためのフォーマット。MLflow Modelsの実態は、任意のファイルと、そのモデルが使用できるいくつかの「フレーバー」を記載したファイルを含むディレクトリとして保存される。MLモデルのフレーバーが学習環境とデプロイ環境のマッピングを管理してくれるため、推論の複雑さを大幅に軽減することができる。
MLflow Projectsとの違いは、MLflow Projectsが実行の再現性とコードのパッケージングに焦点を当てているのに対し、MLflow Modelsは様々なデプロイメント環境に焦点を当てている点である。
MLflow Modelsの構成要素

ML modelに含まれる情報
・モデルの作成時間: モデルが作成された日付と時刻。
・ランID:
モデルがMLflow Trackingを使用して保存された場合は、モデルを作成したランのIDが記録される。
・signature: モデルの入力と出力のスキーマがJSON形式で記録される。モデルの入出力はカラムベースかテンソルベースのいずれかになる。カラムベースの入出力は、MLflowのデータ型の1つとして指定された名前の付いたカラムのシーケンスとして記述することができる。テンソルベースの入出力は、numpyのデータ型の1つとして指定された名前の付いたテンソルのシーケンスとして記述することができる。
・入力データ例: 入力データ例が格納されているアーティファクトへの参照パス。
・databricks runtime: Databricksノートブックまたはジョブでモデルを学習した場合は、Databricksランタイムのバージョンとタイプが記録される。
・フレーバー:
デプロイメントツールがモデルを解釈するために使用するフォーマット(規約)のこと。フレーバーを用いることで、それぞれのMLライブラリをデプロイメントツールに組み込むことなく、デプロイメントを行うことができる。MLflowでは、組み込みデプロイツールがサポートしている「標準」フレーバーが定義されており、Python関数としてモデルを実行する方法を記述した「Python関数」フレーバーなどが存在する。特定のモデルがサポートするすべてのフレーバーは、YAML 形式の ML model ファイルで定義されている。例えば、mlflow.xgboostは以下のようなモデルを出力する。
- MLflow Modelsの構成例:
mlflow.xgboost.log_model(model, "my_model")が書き出したディレクトリ
my_model/ ├── ML model ├── conda.yaml ├── input_example.json ├── model.xgb └── requirements.txt
- ML modelファイル例
artifact_path: model flavors: python_function: data: model.xgb env: conda.yaml loader_module: mlflow.xgboost python_version: 3.8.10 xgboost: data: model.xgb model_class: xgboost.core.Booster xgb_version: 1.5.0 run_id: a9b64d96cb834b31aee30d85d8eff586 signature: inputs: '[{"name": "fixed_acidity", "type": "double"}, {"name": "volatile_acidity", "type": "double"}, {"name": "citric_acid", "type": "double"}, {"name": "residual_sugar", "type": "double"}, {"name": "chlorides", "type": "double"}, {"name": "free_sulfur_dioxide", "type": "double"}, {"name": "total_sulfur_dioxide", "type": "double"}, {"name": "density", "type": "double"}, {"name": "pH", "type": "double"}, {"name": "sulphates", "type": "double"}, {"name": "alcohol", "type": "double"}, {"name": "is_red", "type": "long"}]' outputs: '[{"type": "tensor", "tensor-spec": {"dtype": "float32", "shape": [-1]}}]' utc_time_created: '2022-02-28 05:47:32.105856'
フレーバーの種類
MLモデルのフレーバーは学習環境とデプロイ環境のマッピングを管理するため、MLモデルのフレーバーを使用すれば推論時に学習環境とデプロイ環境のマッピングを行う必要がない。MLflowは標準フレーバーとして各MLモデルをサポートしているが、自作することも可能である。
標準フレーバー例
Python Function (mlflow.pyfunc)
Keras (mlflow.keras)
Scikit-learn (mlflow.sklearn)
Spark MLlib (mlflow.spark)
TensorFlow (mlflow.tensorflow)
XGBoost (mlflow.xgboost)
LightGBM (mlflow.lightgbm)
*参照元: MLflow Models — MLflow 1.28.0 documentation
例えば、以下のような2つのフレーバーが記述されているML modelファイルの場合は、sklearnまたはpython_functionモデルフレーバーのいずれかをサポートする任意のツールで使用することができる。
flavors: sklearn: sklearn_version: 0.19.1 pickled_model: model.pkl python_function: loader_module: mlflow.sklearn
基本的な操作
MLflow Modelsを作成する
フレーバー関数を使ってMLflow Modelsを作成できる。

MLflow のパッケージをインポートする。
import mlflow
モデルをMLflow Modelsとしてパッケージングする。
mlflow.pyfunc.log_model("random_forest_model", python_model=wrappedModel, conda_env=conda_env, signature=signature)
モデルを読み込む。
model = mlflow.pyfunc.load_model(f"models:/{model_name}/production")
読み込んだモデルを使って推論する。
model.predict(X_test)
作成したMLflow Modelsを確認する
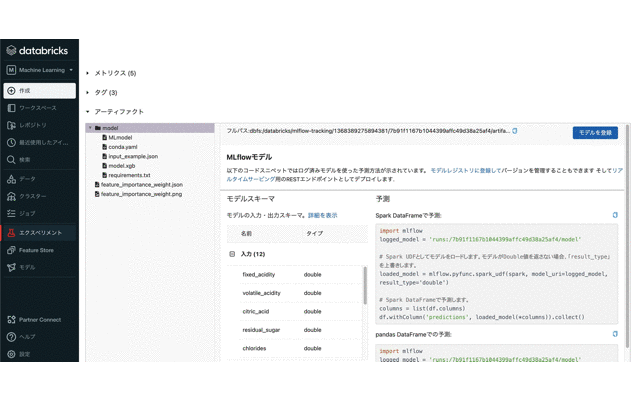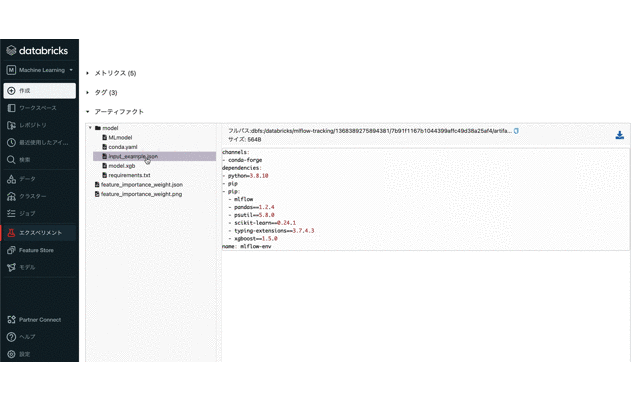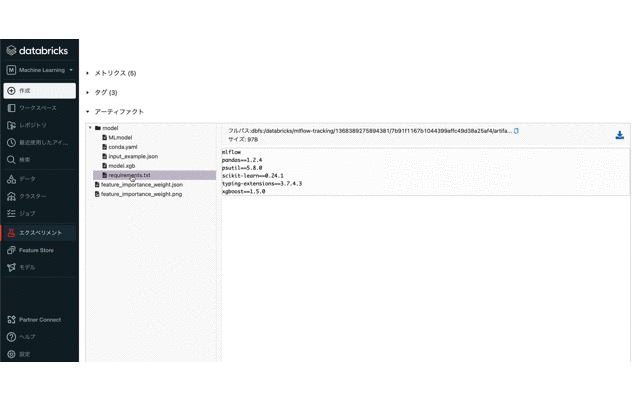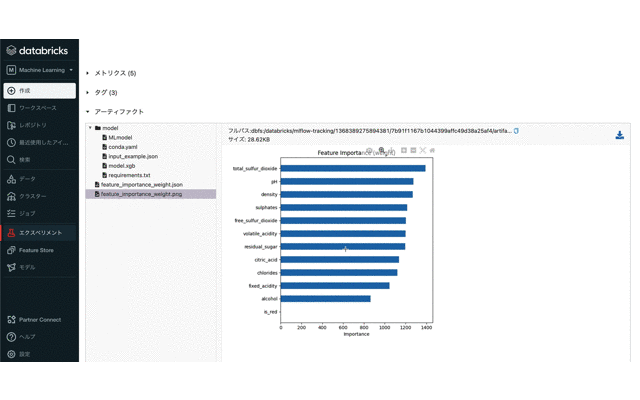
まとめ
今回はMLflow Modelsを使用したモデルの管理についてまとめた。次回はMLflow Model Registryについてまとめる。